Data Driving
Data I/O modes
My goal is to have the vast majority of data (if not everything) loadable/configured from data files. Sometimes I might want to reload the data, while the game is running. I also want to be able to implement save/load functionality at some point. Additionally, I frequently want to visualize/display the data, for debugging/logging purposes. All these are constraints in the design of a data-driven system, and it's definitely not a simple problem to solve.

So, there are effectively 3 types of data transformation:
- Bidirectional 1:1 transformation of data to save state
- This is essential for save games, should take care of smart pointers, etc. I've decided to use cereal for that.
- Display of data
- This is essential for debugging, to be able to visualize the state of the program (as a collection of data) at any given time. This is achieved by overloading the ostream << operator. Class hierarchies use an overridable member function to stream out.
- Initialization of data from config
- This is essential for initialization (duh), as we need to provide a description of how the data should be created, in a concise form. I've decided to use JSON for that. This part has become the most complicated, as it needs to handle everything under the sun: templated classes, class hierarchies, smart pointers, etc. Every new class that is added, and contains some form of data which could be driven from a file, supports such initialization. In addition to initialization, it's useful to support unload/reload, in case we want to dynamically want to alter data.
Resources: Native and Add-ons
Every bit of data that supports initialization from config, is a Resource. Resources support loading/unloading/reloading from JSON. There are two types of resources: native and add-on (ok, I'm not that good with naming). Native resources inherit from Resource class, that provides the appropriate interface for related actions. They store the JSON source and can reload themselves from that. Some of these native resources are polymorphic: they store a pointer to a base class while factory methods create instances based on the JSON config. Add-on resources are objects that we support initialization from JSON, but they are otherwise regular objects with no association to resources, e.g. a vec4 or a map<T,U>. Of course, add-on resources can contain normal resources, that can contain other add-on resources, etc.
Configuration inheritance, Registry and special keys
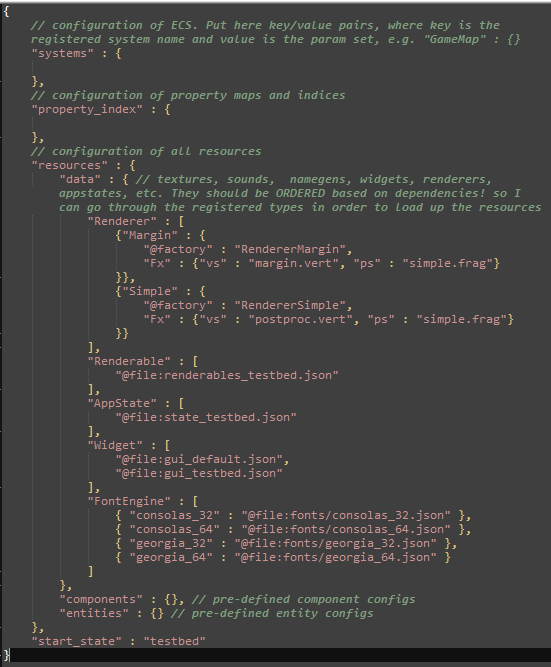
First, very important: all resources that get loaded, are stored into registry by a given name for easy retrieval. Names have power, which we'll harness for the a convoluted part of initialization: configuration inheritance.
Sometimes resources share partial configuration with other resources. To avoid having to duplication configuration parameters, the config system supports configuration inheritance: the configuration of a resource can contain an "@inherit" key, whose value is a registry entry name. The registry entry is cloned and used as a starting point for the rest of the initialization. For simplicity reasons, there's no multiple inheritance.
"@inherit" is a special key, which is handled differently to other keys, as it specifies a registry entry to inherit from. Similarly, there's "@file", which loads the content of another json file at that spot. Additionally, there's "@factory" which specifies the factory to be used to create a polymorphic object. After an object has been constructed using "@factory", or cloned using "@inherit", it initializes itself further using the rest of the JSON block.
And with the above, here's an example JSON file: